
In today’s Brainyacts we:
break down proprietary LLMs
highlight a company making LLM training affordable
give you a new ‘technology law ‘
make a bold prediction on AI-powered law firms
help a judge with an evidentiary dilemma on deepfake voices
see the future Jarvis from Avengers
find another lawyer who relied on ChatGPT 🤦
get another judge to issue an AI disclosure requirement
learn AI can win a Grammy
enjoy a meme
👋 Welcome to Brainyacts 2.0.
It is great to be back at it. This is a long one but only because of the subject matter. Going forward I will continue to make this newsletter digestible and easy to manage while still being pragmatic.
As always, I welcome feedback either with the quick survey at the end of each edition or by just dropping me a line by replying directly to this email.
To reach previous posts, click here.

🎯🚀 Proprietary LLMs Are Here: You Ain’t See Nothin’ Yet
Quick Read (TL;DR):
The AI landscape is shifting with the introduction of Proprietary Large Language Models (LLMs), offering a new level of personalization and high security.
LLMs, tailor-made to suit individual needs, are set to revolutionize industries, especially the legal sector.
High costs and limited talent no longer constrain the development and implementation of these models.
Platforms like MosaicML are making it possible to create customized, efficient LLMs that are both affordable and highly effective.
The use of Chinchilla Scaling Laws is optimizing the training process, leading to more efficient and accurate models.
With the advent of these technologies, we are on the brink of an AI revolution with the potential for entirely AI-powered law firms in the near future.
Proprietary LLMs present an exciting opportunity for businesses of all sizes to tap into the power of advanced AI while ensuring data privacy and security.
Long Read:
Large Language Models (LLMs) have dominated recent generative AI advancements. But as we step into a new era of AI, proprietary LLMs, specifically designed and owned by individual firms or legal teams, are about to cause a seismic shift in the industry.
What are Proprietary LLMs?
Large Language Models are sophisticated AI systems capable of understanding, generating, and interacting with human language. They learn from massive amounts of text data and use that understanding to generate human-like responses or to predict future texts based on the given context. However, these general-purpose LLMs (Open AI, Bard, Anthropic) have been a common property, available to all, with little to no customization.
Proprietary LLMs, on the other hand, are specialized language models, owned and maintained by specific organizations, legal firms, or teams. These models are tailor-made, trained, and refined on the organization's unique data set, thereby providing personalized and high-precision outputs pertinent to the organization's needs.
Why Are Proprietary LLMs Special?
The uniqueness of proprietary LLMs lies in their specificity and security. Firstly, they offer personalized results by learning from the unique datasets of the respective organizations. This ensures that the output generated is specifically tailored to the firm's needs, incorporating professional jargon, firm-specific terms, and preferred styles.
Secondly, and perhaps most importantly, proprietary LLMs provide unparalleled security. Organizations often have reservations about sharing sensitive data with commonly used AI models, considering the potential privacy risks. Proprietary LLMs solve this issue by keeping the data within the organization's controlled environment, hence eliminating any chance of data leakage or unauthorized access.
No Longer Cost or Talent Prohibitive
Contrary to popular belief, the development and implementation of proprietary LLMs are no longer cost or talent prohibitive. Advancements in technologies, techniques, and more understanding of what is going on in the training and learning of these models, have significantly reduced the barriers to entry. More affordable and accessible machine learning platforms will democratize the creation of these custom models, making it a reality for a wider range of organizations. Furthermore, with AI literacy becoming an increasingly standard skill in the tech industry, the talent pool necessary to create and maintain these models is steadily growing.
The Future of Generative AI in Legal (Any) Sector
The holy grail for generative AI, particularly in the legal sector, is to seamlessly access the most suitable AI general-purpose model while also utilizing organization-specific data, with absolute assurance of privacy and security. This goal is not far from realization, with the advent of proprietary LLMs.
In the near future, legal firms, teams, and aid groups will be able to combine their own data with that of the best-performing models through a single interface, without ever sharing any of their data externally. This means they will have the dual advantage of reaping the benefits of massive, well-trained AI models, while also ensuring their data stays secure within their own ecosystem.
Why is this future so near?
The following is an example from a company called Mosiac ML (Machine Learning). They just hit on some fundamental breakthroughs.
MosaicML: Makes Affordable Proprietary LLMs Possible
As you know, the ability to independently train massive AI models from scratch was the prerogative of a select few, well-resourced organizations boasting deep technical expertise. Everyone else has had to resort to renting from API providers who supplied generic, one-size-fits-all models and imposed substantial restrictions on content and usage. Or just using the raw front-end of these models hoping that they can prompt them correctly and safely.
However, MosaicML, a deep learning platform, is on a mission to democratize access to and control over these powerful models, challenging the status quo in a big way.
MosaicML aims to make LLMs not just efficient but also tailored to individual needs. They're working to reduce training costs and timeframes, thus enabling anyone to create a custom LLM to meet specific needs, such as an LLM pre-trained on medical journals for a healthcare organization, instead of relying on models trained on generic data like Reddit threads.
Recently, MosaicML announced a significant milestone on this path: they now offer first-class support for training LLMs on their platform and, importantly, provide full transparency about the associated costs. Contrary to popular belief, they reported that training a model to GPT-3's quality could cost about $450K - a far cry from the $1M to $5M many assumed.
MosaicML has also presented compelling evidence to dispel the cost myth. They trained a compute-optimized GPT-30B model on their platform using 610 billion tokens, achieving GPT-3 quality performance for less than $500K. Remarkably, this was accomplished with fewer parameters than GPT-3 but with more data, in line with the new Chinchilla scaling law (see below).
Going forward, MosaicML plans to optimize their training recipes even further, reducing costs and making it feasible for anyone to independently analyze, train, and deploy these models. Their vision is to usher in a future with millions of unique models trained on diverse datasets for specific applications.
If MosaicML's efforts bear fruit, we could see a shift in AI dynamics, where businesses, researchers, and students alike can readily access and train custom LLMs, breaking free from the restrictions of conventional, generic models.
Chinchilla Scaling Laws: A Recipe for Efficient Language Model Training
You’ve heard of Moore’s law, right? It means that over time, computer chips can become smaller, faster, and more powerful as more and more transistors can be packed onto them. This trend has been a driving force behind the advancements in technology we've seen in recent decades.
Well, the Chinchilla scaling laws provide a set of rules that help researchers and developers train large language models more efficiently. Just like a recipe guides you on the amount of ingredients needed to make a dish, these laws guide the amount of data required to train a language model of a specific size. By following these rules, researchers can optimize the training process and make better use of their resources.
Key Points:
Chinchilla Scaling Laws: These laws were proposed in a DeepMind paper and are used to determine the amount of training data needed for optimal training of a Large Language Model (LLM) of a given size.
Data-Optimal Model Size: The laws suggest that around 1.4 trillion tokens (1,400 billion tokens) should be used to train a data-optimal LLM with a size of 70 billion parameters.
Tokens per Parameter: According to the Chinchilla scaling laws, approximately 20 text tokens are needed per parameter during training.
Importance of Chinchilla Scaling Laws:
Efficient Model Training: By knowing how much data is needed to train a language model of a specific size, researchers can optimize the training process and reduce the time and resources required.
Resource Optimization: The Chinchilla scaling laws help make better use of computational resources by providing guidelines on the relationship between model size and training data.
Improved Performance: Following these laws ensures that language models are trained with the right amount of data, resulting in improved performance and accuracy.
✔️ 🔮 PREDICTIONS
Think of a paradigm where deep learning is accessible to all, regardless of the size of the business. Initiatives that support training LLMs, making their cost transparent and more economical, are gradually becoming a reality. This heralds an exciting shift that enables all businesses, legal services, and non-profits to tap into the power of cutting-edge AI models and their own data, all while ensuring data privacy and security.
MOST BOLD - We will have an AI-powered law firm (at least 50% plus of all work - operations and legal services - done by AI - within 1 year
#1 The rise of proprietary models will unlock the business model changes within legal services that many have urged or warned about for ages.
More specifically, as AI-powered legal technology matures, it will become increasingly customized and proprietary. In other words, law firms will start to build or commission their own AI models tailored to their specific needs. This will drive a significant shift in business models in legal services. For instance, traditional law firms, which are generally based on billable hours, may move towards models that prioritize the value provided to clients - be it speed, consistency, or depth of insight. This shift could result in faster, more efficient legal processes, but may also risk exacerbating inequality in access to legal services if the technology remains expensive and inaccessible to smaller firms or those who cannot afford to invest.
#2 It will start in the operations or business side of firms. Slowly and unevenly it will migrate to practices through augmented services and products that displace both traditional legal talent and many billable work tasks.
The first areas of law firms to adopt these AI models will likely be operations and business functions. These are areas where efficiency gains and cost savings can be quickly realized and where there may be less resistance to change. Over time, AI will start to permeate the practice of law itself, leading to 'augmented' legal services where AI assists or even replaces human lawyers for certain tasks. This could involve everything from drafting contracts to conducting legal research or predicting the outcome of cases. However, this transformation will not be evenly distributed across all areas of law or all firms, and it may also raise ethical and regulatory issues around the role of AI in the practice of law.
#3 Many law firms will figure out their economic model in order to raise fees in order to cover lost billable time.
As AI starts to take over tasks previously done by human lawyers, law firms will have to rethink their economic models. If AI reduces the time lawyers spend on billable tasks, firms may have to find other ways to maintain their revenue. This could involve raising fees for certain services, but it could also involve finding new value propositions for clients – for example, by offering more strategic advice or consultancy services, or by using AI to provide better, more predictive legal insights.
#4 Many firms will ignore this or dampen advancements - they will survive without question, but their legacy will be that of a ‘has been.’
Not all firms will be quick to adopt AI. Some may be skeptical of the technology, resistant to change, or simply lack the resources to invest in AI. These firms may continue to operate using traditional models, but they risk becoming less competitive over time as other firms leverage AI to deliver more efficient and innovative services. They will still survive, at least in the short to medium term, but they may be seen as lagging behind or out of touch with the latest advances in legal technology.
👩⚖️🤯 Meta Gives Judges a New Headache
In the Brainyacts AMA group (ask me anything), we have a retired judge who is preparing to teach over 100 judges about generative AI. He asked us for some thoughts on what things we would want our judge to know about AI if we had a case in front of them. It was an intriguing query and filled with innumerable choices and rabbit holes.
Here was his request:
What do you see as the most important things judges must understand about AI in order to render decisions involving their gatekeeping function on authenticity and admissibility of evidence as well as the role of AI in eDiscovery and written advocacy. What would you want your judge to know about AI when you present your case or oppose the other side's case?
I tried to offer up something intelligent. One thing that struck me was the use of AI-generated voice. This is such a challenge in that we are quickly getting to a point for AI-generated voices are almost imperceptible from natural human voices. And more tools are being released and democratized as we speak.
Here is Mark Zuckerberg sharing Meta’s new tool:
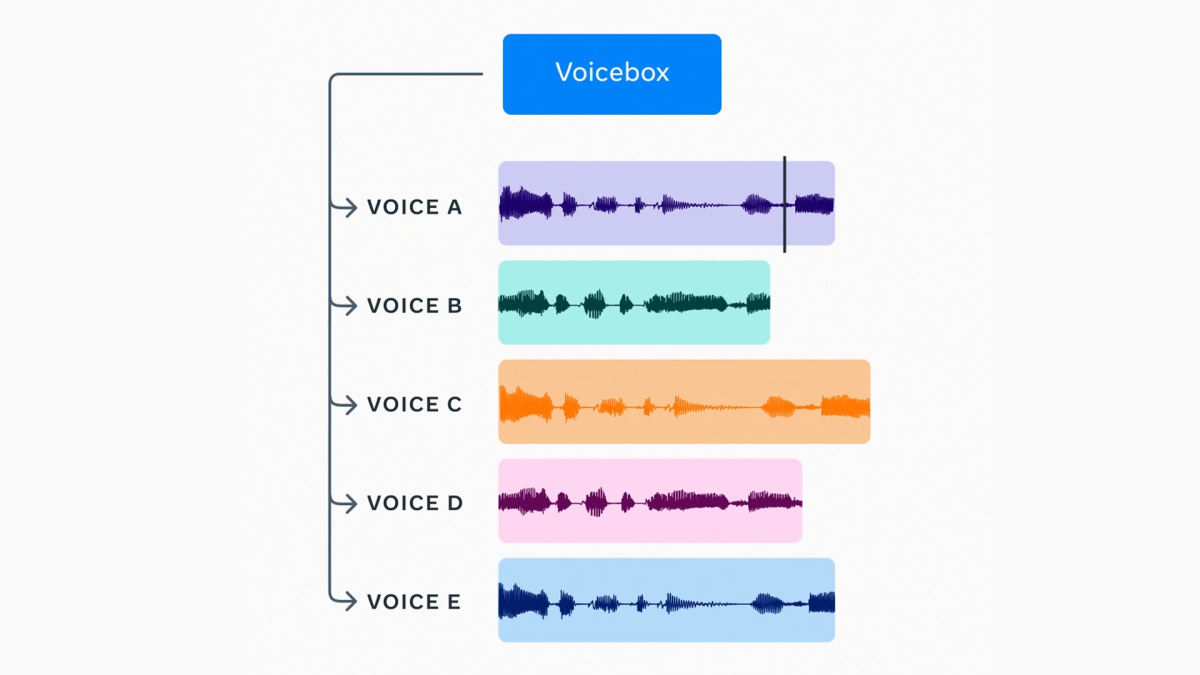
Can you imagine the challenge judges will have even accepting voice recordings at face value? They have always been troublesome to admit into evidence, but now, well how can a judge take any recording without questioning if it was AI-generated or altered in some way?
The use of voice recordings as evidence in the U.S. legal system presents several challenges, and the advent of AI-generated voices is likely to exacerbate these.
Here are some key issues:
Pre-AI-generated voice proliferation
Authenticity: The primary issue with voice recordings is proving that they are genuine and haven't been tampered with. The court must establish a chain of custody, showing who had access to the recording and when to help ensure its integrity.
Consent: Depending on the jurisdiction, one or all parties involved in the recording might need to consent to being recorded. This can create legal complications, especially when the recording is conducted without the knowledge or consent of one or more parties.
Quality and clarity: Poor audio quality or lack of clarity can lead to disputes about what was said or who said it. Background noise or the use of technical or unclear language can create ambiguity.
Identification: Voice identification can be a challenging issue. Unless the person in question has a particularly distinctive voice, or they self-identify in the recording, it can be hard to prove that the voice belongs to a particular person.
Context: Without proper context, recorded conversations can be misleading or easily misconstrued. A statement that appears incriminating in isolation might have a benign meaning in the full context of the conversation.
In the generative AI era
The advent of AI-generated voices – or 'deepfake' voices – adds another layer of complexity to these challenges.
Increased Doubt About Authenticity: With the rise of sophisticated AI technologies, it is becoming increasingly easy to create realistic voice deepfakes. These can simulate a person's voice so effectively that it can be challenging to distinguish between the fake and the real voice. This could lead to more frequent objections and legal arguments about the authenticity of voice evidence. What is a judge to do?
More Complex Identification Process: AI-generated voices could blur the lines of identification further. If AI can mimic a person's voice perfectly, it could be difficult to prove whether a certain statement was made by the actual person or an AI impersonation. This might necessitate the use of advanced voice analysis technologies or experts to verify the identity of the speaker. How will this increase costs and time?
Potential for Abuse: There is a risk that AI-generated voices could be used maliciously, such as creating false evidence or defaming individuals. For example, an individual or entity could use AI to create a recording of someone appearing to confess to a crime or make controversial statements they never actually made. This could result in a potential increase in legal disputes and trials centered around the validity and source of such recordings. Again, costs and time.
Legal Frameworks and Policies: Existing legal frameworks may not adequately cover AI-generated voice recordings, meaning that legislation might need to catch up. This raises questions about consent and legality, particularly in cases where an individual's voice is used without their knowledge or permission. How does someone prove they didn’t say something?
Standard of Proof: Proving that an AI-generated voice was used instead of a real person's voice could be difficult, requiring highly sophisticated audio analysis tools. This can further complicate proceedings and potentially increase the standard of proof required. Ugh, the costs and time again!
For those that want to go deep into how US judges have been handling AI and evidence prior to the generative era, here is an article in which former District Court Judge Paul Grimm articulates an approach.
Thank you for your query and also for sharing this article, Judge Artigliere
🔩🐙 Building Jarvis
Any Avengers and Tony Stark fans out here? If so, you know how amazing it is to be able to talk with a computer. For those that need an intro or a refresher, here is a short video.
But more importantly, check out this early demo of speaking to a computer in a natural way so that the AI understands and composes text. There is dictation and auto-complete - but this is net level. Is it perfect? No. Is it early? Yes.
Imagine the productivity gains in legal with something like this. Add to it the ability of text-to-speech and not only could you speak to write, you could then refine and edit as AI reads it back to you.
News you can Use:
Another Lawyer Steps In ‘It’ By Relying on ChatGPT
/cloudfront-us-east-2.images.arcpublishing.com/reuters/L4VK72FSCFLAXE4XALVNRQSNOA.jpg)
Another Judge Gets Into AI Certification Arena

AI Can Win A Grammy

In the Memetime:

Was this newsletter useful? Help me to improve!
DISCLAIMER: None of this is legal advice. This newsletter is strictly educational and is not legal advice or a solicitation to buy or sell any assets or to make any legal decisions. Please /be careful and do your own research.8